Appearance
九、SSE 实时同步稳定性深度优化
本章记录了将 TodoApp 的 SSE 实时同步从"经常单向死寂、必须重启恢复"优化到"稳定双向同步、断线秒级恢复"的完整过程,包含架构设计、疑难 Bug 排查和底层机制分析。
9.1 问题背景
初始症状
TodoApp 上线后,实时同步的稳定性远低于预期,主要表现为三种故障模式:
| 故障模式 | 具体表现 | 频率 |
|---|---|---|
| 单向死寂 | 设备 A 的操作能同步到设备 B,反向不行 | 高频 |
| 双向静默 | 两端都收不到更新,操作像在孤岛上 | 中频 |
| 幽灵连接 | 后端日志显示连接数持续增多,重启后恢复 | 低频 |
所有故障的共同特征:重启应用可以恢复,说明问题出在运行时的连接状态管理上,而非数据逻辑。
根因分类
经过系统排查,问题根因分为三类:
后端:僵尸连接污染连接池
客户端因网络原因静默断开后,后端的 StreamController 没有被及时清除,依然留在 EventBroadcaster 的连接池里。广播时向僵尸连接发送数据,add() 抛异常被吞掉,该客户端永远收不到推送。
客户端:Stream 假死不触发重连
静默断网(用户走进信号盲区)时,TCP 协议栈的重传机制使得 onError / onDone 可能在几分钟后才触发,甚至永远不触发,客户端的 Stream 看起来"活着",实际上永远不会再收到数据。
断线期间数据丢失
SSE 是广播推送,不具备历史重放能力。断线重连期间,其他设备的变更会被漏掉,重连后本地数据与服务端不一致。
9.2 诊断过程
通过日志定位问题
后端 ServerLogger 会记录每次 SSE 连接和心跳探活结果。关键日志模式:
正常状态:
[SSE ] 用户连接 userId=xxx deviceId=yyy 在线总数=2
[SSE ] 心跳探活:存活 2 个连接僵尸连接:
[SSE ] 心跳探活:清除 1 个僵尸连接,存活 1 个同设备重连(异常):
[SSE ] 同设备重连,清理旧连接 deviceId=xxx
[SSE ] 用户连接 userId=xxx deviceId=xxx 在线总数=1 ← 总数没有增加关键诊断指标:如果两台设备同时在线,"存活 N 个连接"的 N 应该等于在线设备数。N 小于设备数说明有连接没建立;N 大于设备数说明有僵尸连接没清理。
9.3 五层防护体系
优化后的架构由五层防护组成,每层解决一类独立的问题:
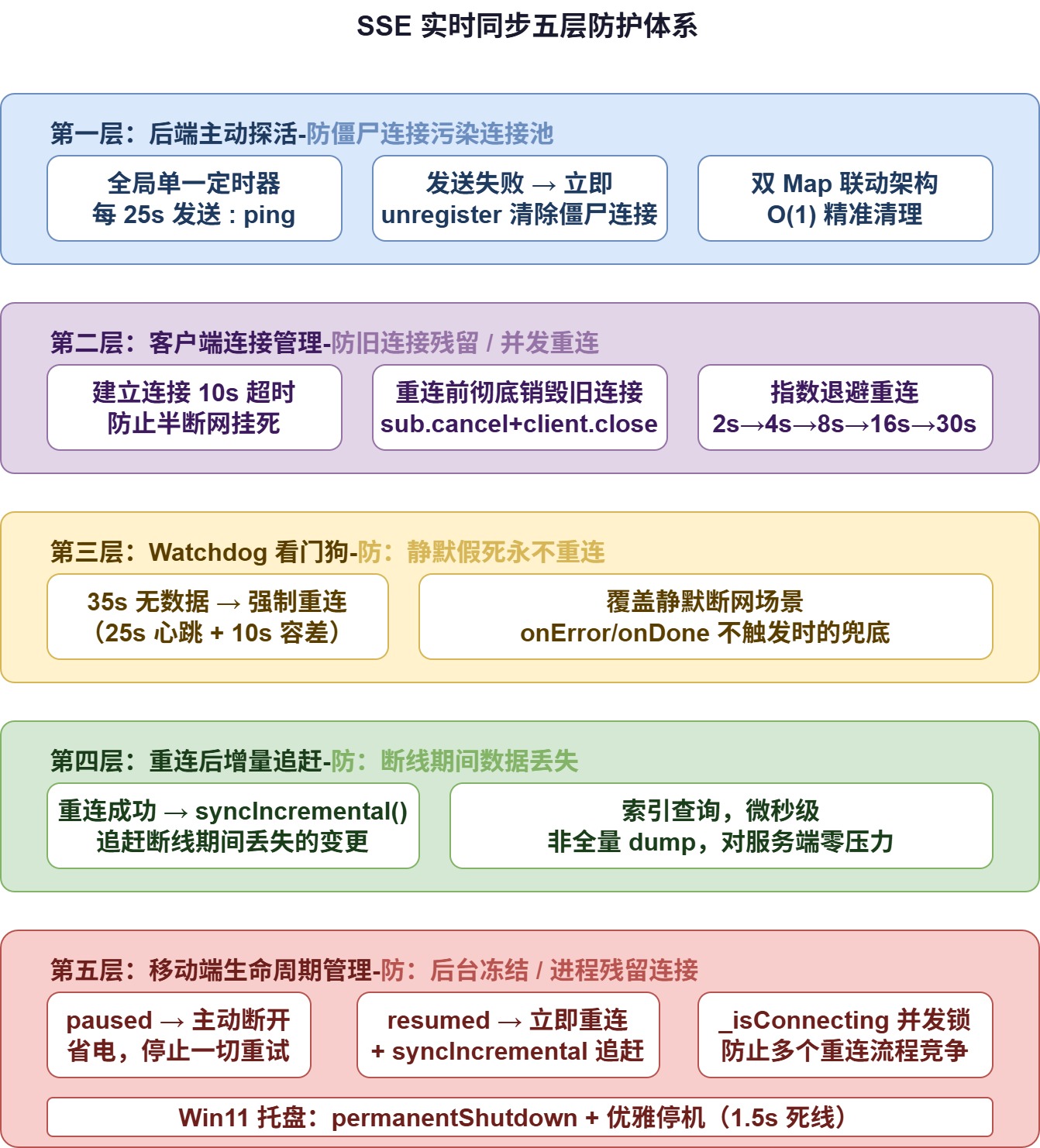
五层防护相互独立,每层都可以单独解决一类问题,叠加后覆盖了所有已知的故障场景。
9.4 第一层:后端主动探活
原有设计的缺陷
最初的后端心跳是每个连接独立一个定时器,心跳逻辑如下:
dart
// 原有实现:N 个连接 = N 个定时器,资源浪费
final timer = Timer.periodic(const Duration(seconds: 20), (_) {
send(': ping\n\n'); // 发送失败也只是打印日志,不清理连接
});两个缺陷:一是 N 个连接就有 N 个定时器,资源浪费;二是发送失败只打日志,僵尸连接不会被清除。
双 Map 联动架构
重构后的 EventBroadcaster 用两个 Map 分别服务于不同场景:
| Map | 键 | 值 | 用途 |
|---|---|---|---|
connections | userId | List<StreamController> | 广播时按用户查找,O(1) |
_deviceConnections | deviceId | _ConnectionEntry(userId, ctrl) | 精准操作按设备查找,O(1) |
_ConnectionEntry 同时存储 userId 和 ctrl,使得通过 deviceId 可以 O(1) 找到对应的 userId,进而同步清理 connections Map,保证两个 Map 始终一致。
dart
class _ConnectionEntry {
final String userId;
final StreamController<List<int>> ctrl;
_ConnectionEntry(this.userId, this.ctrl);
}心跳即探活
全局单一定时器,每 25 秒遍历 _deviceConnections,尝试向每个连接发送 : ping\n\n,发送失败立即 unregister:
dart
void _sendHeartbeat() {
for (final deviceId in List.of(_deviceConnections.keys)) {
final entry = _deviceConnections[deviceId];
try {
entry.ctrl.add(_pingPayload);
} catch (_) {
unregister(deviceId); // 发送失败 = 僵尸连接,立即清除
}
}
}同设备防重入
客户端断网重连时,旧连接可能还没被心跳清理,新连接注册进来,同一 deviceId 就会有两条连接。register() 在注册新连接前先检查:
dart
void register(String userId, String deviceId, StreamController ctrl) {
final old = _deviceConnections[deviceId];
if (old != null) {
_removeEntry(deviceId, old); // 先清理旧连接
}
connections.putIfAbsent(userId, () => []).add(ctrl);
_deviceConnections[deviceId] = _ConnectionEntry(userId, ctrl);
}9.5 第二层:客户端连接管理
连接建立 10s 超时
http.Client.send() 在网络半断状态下会永远挂住,导致 _isConnecting = true 永远不释放,之后所有重连尝试都会被并发锁拦截:
dart
final response = await _client!
.send(request)
.timeout(const Duration(seconds: 10)); // 防止半断网挂死重连前彻底销毁旧连接
仅 cancel() 订阅不够,还需要 close() HTTP client,确保旧的 TCP 连接彻底释放:
dart
void _destroyConnection() {
_sub?.cancel();
_sub = null;
_client?.close(); // 必须关闭,否则旧 TCP 连接残留
_client = null;
}并发锁
多个重连触发源(onDone、onError、Watchdog、生命周期)可能同时发起重连,_isConnecting 布尔锁确保同一时间只有一个连接流程:
dart
if (_isConnecting) {
AppLogger.sse('已有连接流程在进行中,跳过本次');
return;
}
_isConnecting = true;指数退避算法
标准二的幂次退避,封顶 30 秒:
dart
final delaySecs = min(30, pow(2, _retryCount).toInt());
// 第1次: 2s → 第2次: 4s → 第3次: 8s → 第4次: 16s → 第5次起: 30s避免断网时客户端疯狂轰炸服务端,对服务端友好,同时保证恢复后能及时重连。
9.6 第三层:Watchdog 看门狗
静默断网的致命陷阱
在处理 SSE 稳定性时,最难对付的场景是静默断网(Silent Drop):用户手机进入地铁隧道,网络信号消失,但 TCP 协议栈不会立刻抛出 SocketException。
此时后端尝试发送心跳,数据积压在操作系统的发送缓冲区,ctrl.add() 不会立即抛异常(可能延迟几分钟)。客户端的 Stream 订阅既不会触发 onError,也不会触发 onDone,就这样傻傻等待,永远不会重连。
连接建立时的 10s 超时只作用于握手阶段,一旦进入数据接收状态就完全失效,无法解决静默假死问题。
Watchdog 设计
解决方案是引入看门狗定时器:只要超过阈值时间没有收到任何数据(包括心跳),就主动强制重连。
阈值设计:后端心跳间隔 25s,加上 10s 网络容差,Watchdog 阈值设为 35 秒。
dart
static const _watchdogSecs = 35; // 25s 心跳 + 10s 容差
void _resetWatchdog() {
_watchdogTimer?.cancel();
_watchdogTimer = Timer(const Duration(seconds: _watchdogSecs), () {
if (_isShuttingDown) return;
AppLogger.w('Watchdog 超时(${_watchdogSecs}s),强制重连', tag: 'SSE');
_stopWatchdog();
_sub?.cancel();
_sub = null;
_client?.close();
_client = null;
_isConnecting = false;
_scheduleReconnect();
});
}核心原则:收到任何数据(包括 : ping 心跳注释行)都重置 Watchdog:
dart
_sub = response.stream.transform(utf8.decoder).listen(
(chunk) {
_resetWatchdog(); // 有数据到来,说明连接存活,重置计时
_processChunk(chunk);
},
...
);注释行 : ping\n\n 虽然不携带业务数据,但它触发了 onData 回调,Watchdog 得以重置。这正是后端心跳设计的关键作用:不只是防止 Nginx 切断长连接,还是客户端存活检测的信号源。
Nginx 与心跳的协调
三个参数的设计需要相互配合:
| 参数 | 值 | 说明 |
|---|---|---|
| 后端心跳间隔 | 25s | 每 25s 发送 : ping |
| 客户端 Watchdog | 35s | 25s + 10s 容差 |
| Nginx keepalive_timeout | 90s | 大于心跳间隔的 3 倍,避免被代理切断 |
9.7 第四层:重连后增量追赶
问题:断线期间数据丢失
SSE 是广播推送,不具备消息队列的历史重放能力。断线期间其他设备发生的任何变更,都不会在重连后补发。
如果重连后不主动拉取,本地数据将与服务端不一致,用户会看到"旧数据",直到下次手动刷新。
重连后触发 smartSync(三路决策)
重连成功的瞬间,触发一次"智能同步",由它决定要不要拉、拉多少:
dart
// 连接成功后
SyncService.instance.hasPendingQueue().then((_) {
_resumedFromBackground = false;
SyncService.instance.smartSync(); // 三路决策:跳过 / 增量 / 全量
});为什么不无脑 syncAll?
syncAll() 会重放离线队列 + 全量拉取,而全量拉取在服务端是全表扫描,断线只有几秒时完全没必要。smartSync() 先比对服务端时间戳:绝大多数抖动重连会判断"已是最新"直接跳过,需要时才走增量(GET /todos/?since=T,updated_at 有索引,微秒级)。
| 方法 | 触发场景 | 服务端开销 |
|---|---|---|
syncAll() | 应用启动、下拉刷新、60min 定时自愈 | 高(全表扫描) |
smartSync() | SSE 重连成功、切回前台、15min 定时兜底 | 极低(时间戳对比,按需增量) |
本层最初的实现是重连后无条件
syncIncremental()。后来发现"抖动重连时对端往往没有变更,增量也成了多余请求",于是升级为基于服务端时间戳的三路决策smartSync()——完整设计见 第十一章:智能同步优化。
9.8 第五层:移动端生命周期管理
Android 后台冻结问题
Android 系统为了省电,当应用切到后台超过一段时间,会冻结应用的网络活动,SSE 连接必然断开。如果不主动处理,用户重新切回前台时会看到旧数据,最长需要等待 35 秒(Watchdog 超时)才能恢复连接,体验上有明显的"卡顿感"。
WidgetsBindingObserver 接入方案
WidgetsBindingObserver 是 Flutter 提供的应用生命周期监听接口,HomeScreen 和 HomeScreenMobile 各自混入并转发给 SseService:
dart
class _HomeScreenMobileState extends State<HomeScreenMobile>
with WidgetsBindingObserver {
@override
void initState() {
super.initState();
WidgetsBinding.instance.addObserver(this); // 注册监听
}
@override
void dispose() {
WidgetsBinding.instance.removeObserver(this); // 移除监听
super.dispose();
}
@override
void didChangeAppLifecycleState(AppLifecycleState state) {
if (state == AppLifecycleState.paused) {
SseService.instance.onAppPaused();
} else if (state == AppLifecycleState.resumed) {
SseService.instance.onAppResumed();
}
}
}为什么不在 SseService 内部注册 WidgetsBindingObserver?
SseService 是业务 Service 层,不应引入 WidgetsBinding 这个 Flutter UI 框架的依赖,违反分层原则。UI 层负责感知生命周期,Service 层只暴露 onAppPaused() / onAppResumed() 两个方法接受调用,职责清晰。
生命周期处理逻辑
App 进入后台(paused)
→ onAppPaused()
→ _active = false
→ 停止 Watchdog + 销毁连接
→ 省电:不再有任何后台网络活动
App 切回前台(resumed)
→ onAppResumed()
→ 检查 _active:若已连接则忽略(防虚假 resumed 事件)
→ _active = true,_retryCount = 1(标记为重连状态)
→ _doConnect() → 连接成功 → smartSync() 三路决策追赶变更为什么检查 _active 再决定是否重连?
Windows 桌面端在用户右键点击托盘图标时,系统可能发送焦点事件,Flutter 将其翻译为 AppLifecycleState.resumed。此时 SSE 连接完全正常(_active = true),如果不检查就直接重连,会触发"同设备重连",不必要地清理了正常连接。
加上 if (_active) return 后,只有真正从后台恢复(onAppPaused 已将 _active 设为 false)才会重连,虚假的 resumed 事件被过滤掉。
Win11 优雅停机
Windows 托盘应用有一个特殊的退出场景:用户点击托盘菜单"退出"。这个回调是同步的 VoidCallback,不能直接 await 异步清理逻辑。
解决方案是 unawaited + 串行清理:
dart
onExit: () => unawaited(_gracefulShutdown()),
Future<void> _gracefulShutdown() async {
// 第一步:物理免疫(同步执行,在任何 await 之前)
// 设置 _isShuttingDown = true,阻断一切重连可能
SseService.instance.permanentShutdown();
// 第二步:切断生命周期信号
// 防止 windowManager.destroy() 触发 onAppResumed
WidgetsBinding.instance.removeObserver(this);
// 第三步:通知后端关闭 SSE(1.5s 死线)
try {
await ApiService.instance.disconnectSse();
} catch (_) {}
// 第四步:销毁进程
TrayService.instance.destroy();
await windowManager.destroy();
}关键设计原则:permanentShutdown() 必须是第一步且同步执行。async 函数在遇到第一个 await 之前是完全同步的,所以 _isShuttingDown = true 在函数开始执行的瞬间就生效,此后任何生命周期事件都无法触发重连。
disconnect() 和 permanentShutdown() 的区别:
| 方法 | 场景 | _isShuttingDown | 可恢复 |
|---|---|---|---|
disconnect() | 退出登录 | 不修改 | ✅ 重新登录后可 connect() |
permanentShutdown() | 进程退出 | 设为 true | ❌ 任何重连都被拦截 |
9.9 疑难 Bug 排查实录
本节记录优化过程中遇到的五个真实 Bug,每个都保留了完整的"症状 → 根因 → 修复"链路。
Bug 1:两台设备共用同一 deviceId,连接数始终为 1
症状
Win11 和 Android 同时登录同一账号,后端日志显示"存活 1 个连接",且不断出现"同设备重连,清理旧连接"。Win 端操作无法同步到 Android,因为后端只维护了一条连接。
排查
查看后端日志中的 deviceId:
同设备重连,清理旧连接 deviceId=device-ca9dc02b-...
用户连接 userId=ca9dc02b-... deviceId=device-ca9dc02b-... 在线总数=1deviceId 的格式是 device-{userId},这是后端的兜底逻辑:
dart
// server.dart
final deviceId = request.headers.value('x-device-id') ?? 'device-$userId';说明两台设备发来的 SSE 请求都没有携带 X-Device-Id Header,后端用相同的 userId 生成了相同的兜底值,两台设备被识别为同一台。
根因
SseService._doConnect() 建立 SSE 连接时,只携带了 Authorization 等 Header,遗漏了 X-Device-Id:
dart
// 修复前:缺少 X-Device-Id
request.headers['Authorization'] = 'Bearer ${...}';
request.headers['Accept'] = 'text/event-stream';
request.headers['Cache-Control'] = 'no-cache';
// ← 没有 X-Device-Id而普通 REST 请求通过 _authHeaders 统一携带了 X-Device-Id,SSE 连接是单独构造的 http.Request,被遗漏了。
修复
dart
request.headers['X-Device-Id'] = AuthService.instance.deviceId;Bug 2:退出登录后连接数不立即减少,最长延迟 1 分 40 秒
症状
用户点击退出登录,POST /auth/logout 返回 200,但后端心跳日志显示连接数不变,直到约 1 分 40 秒后才减少。
排查
auth_handler.dart 的 logout 处理在收到请求后调用了 unregister(deviceId),日志应该立刻打印"用户断开",但实际没有。
查看 server.dart 的 SSE 断开逻辑:
dart
// 等待客户端断开
try {
await response.done; // ← 只靠这个
} catch (_) {}
await sub.cancel();
broadcaster.unregister(userId, ctrl);根因
后端只靠 response.done 等待 TCP 连接关闭。客户端调用 _client.close() 后,TCP 四次挥手需要时间,加上 TCP 的 TIME_WAIT 状态(约 60 秒),response.done 可能在 1-2 分钟后才 complete。如果网络不稳定,TCP RST 包丢失,response.done 可能永远不会 complete。
修复
auth_handler.dart 中 logout 时直接调用 EventBroadcaster.instance.unregister(deviceId),不依赖 TCP 层的感知:
dart
router.post('/logout', (Request req) async {
// ... 删除 refresh_token ...
// 用 deviceId 精准关闭当前设备的 SSE,不影响其他设备
final deviceId = req.headers['x-device-id'];
if (deviceId != null && deviceId.isNotEmpty) {
EventBroadcaster.instance.unregister(deviceId);
}
return Res.ok({'message': '已退出登录'});
});退出后连接立即关闭,下次心跳日志正确显示减少后的连接数。
Bug 3:托盘退出出现幽灵重连
症状
点击托盘菜单"退出"后,后端日志出现"同设备重连,清理旧连接",而不是期望的"用户断开"。进程退出前的最后一刻,客户端向后端建立了一条新的 SSE 连接。
排查
这个 Bug 经历了多轮排查,逐步定位:
第一轮:怀疑 _gracefulShutdown 没有执行。加日志发现它确实执行了,但调用的是 disconnect() 而非 permanentShutdown():
dart
// 错误代码(早期版本)
Future.wait([
ApiService.instance.disconnectSse(),
Future(() => SseService.instance.disconnect()), // ← 没有设 _isShuttingDown
])第二轮:改为调用 permanentShutdown(),但幽灵重连依然出现。
第三轮:发现 TrayService.onExit 的类型是 VoidCallback(同步),而 _gracefulShutdown() 是异步方法:
dart
// TrayService
final VoidCallback _onExit; // 同步!
void onTrayMenuItemClick(MenuItem menuItem) {
case 'exit':
_onExit(); // 调用后不等待,立即返回
}Native 插件的同步回调不会等待 Dart 的 Future,_gracefulShutdown() 里的 async 逻辑还没执行,进程销毁流程就已经开始了。
根因
permanentShutdown() 虽然是同步的(在第一个 await 前就会执行),但实际触发重连的是更早发生的事件:
Windows 右键点击托盘图标打开上下文菜单时,系统会向应用发送焦点事件,Flutter 将其翻译成 AppLifecycleState.resumed,触发 onAppResumed()。此时 _active 可能因为某些原因为 false,onAppResumed() 直接调用 _doConnect(),建立新连接——这才是"同设备重连"的真实来源,与退出流程无关。
修复
两处修复:
onAppResumed()加if (_active) return,防止已连接时的虚假 resumed 事件触发重连:
dart
void onAppResumed() {
if (_isShuttingDown) return;
if (_active) return; // ← 已连接则忽略
...
}_gracefulShutdown()改为串行执行,permanentShutdown()必须是第一步:
dart
Future<void> _gracefulShutdown() async {
SseService.instance.permanentShutdown(); // 第一步,同步,立即生效
WidgetsBinding.instance.removeObserver(this);
try {
await ApiService.instance.disconnectSse();
} catch (_) {}
TrayService.instance.destroy();
await windowManager.destroy();
}Bug 4:优雅停机的 DELETE 请求被路由到错误 Handler
症状
_gracefulShutdown() 调用 ApiService.disconnectSse() 发送 DELETE /events/connection,但后端日志从未出现"优雅停机"字样,unregister 也没有执行。
排查
检查后端的请求分发逻辑:
dart
server.listen((HttpRequest request) async {
if (request.uri.path.startsWith('/events')) { // ← 问题在这里
await _handleSSE(request);
} else {
await shelf_io.handleRequest(request, handler);
}
});DELETE /events/connection 的路径以 /events 开头,被拦截到 _handleSSE() 处理。而 _handleSSE() 专为 SSE 长连接设计,会执行 JWT 验证、建立 StreamController、等待 response.done……把一个普通的 DELETE 请求当成 SSE 握手来处理。
DELETE /events/connection 这个路由在 shelf router 里注册的是正确的,但永远到达不了。
根因
路由分发条件用的是前缀匹配(startsWith('/events')),没有区分 HTTP 方法,导致所有以 /events 开头的请求都被 _handleSSE 拦截。
修复
改为精确匹配:只有 GET /events/ 才走 SSE 处理:
dart
server.listen((HttpRequest request) async {
if (request.method == 'GET' && request.uri.path == '/events/') {
await _handleSSE(request);
} else {
await shelf_io.handleRequest(request, handler); // DELETE /events/connection 走这里
}
});Bug 5:启动时 SSE 因 Token 过期永久放弃连接
症状
应用启动后,后端长时间没有"用户连接"日志。但其他 REST 接口(如 GET /todos/)正常工作,说明 Token 已经刷新成功,只有 SSE 连接没有建立。
日志显示,约 1 分钟后(经过几轮指数退避)SSE 才连接成功。
排查
initState 里的调用顺序:
dart
SyncService.instance.syncAll(); // 异步,立刻返回,在后台执行(内部会刷新 token)
SseService.instance.connect(); // 立即执行,此时 token 可能还没刷新syncAll() 是异步的,不等待它完成,connect() 紧接着用过期的 token 发起 SSE 连接,收到 401。
原有的 401 处理逻辑:
dart
// 修复前:401 直接永久放弃
if (response.statusCode == 401) {
_active = false; // 永久停止
return;
}_active 被设为 false,之后没有任何机制触发重连,SSE 就死了——直到用户触发其他能调用 connect() 的操作(比如切换前后台)才能恢复。
根因
启动时存在竞态条件:syncAll() 的 Token 刷新和 connect() 的 SSE 建立是并发的,SSE 先到,用的是旧 Token,收到 401 后不应永久放弃,而应等待 Token 刷新完成后重试。
修复
401 不再永久放弃,改为计数重试,连续 3 次 401 才真正停止:
dart
int _authFailCount = 0;
if (response.statusCode == 401) {
_isConnecting = false;
_authFailCount++;
if (_authFailCount >= 3) {
_active = false;
_authFailCount = 0;
AppLogger.sse('SSE 认证连续失败 3 次,停止重连');
return;
}
AppLogger.sse('SSE 认证失败($_authFailCount/3),等待 token 刷新后重试');
_scheduleReconnect(); // 进入退避队列,等 token 刷新
return;
}
// 连接成功时归零
_authFailCount = 0;修复后的启动流程:
connect() 用旧 token 发起 SSE → 401
→ _authFailCount = 1,等 2s 重试
syncAll() 刷新 token 完成(约 50ms)
→ 2s 后重试,用新 token
→ SSE 连接成功整个过程约 2 秒,用户无感知。
Bug 6:Android 后台唤醒时多端数据不一致
症状
Android App 长时间在后台后切回前台,SSE 重连成功,但 Win 端看不到 Android 离线期间的操作,两端数据不一致。同时偶发 SocketException: Failed host lookup (errno=7) 导致重连失败。
排查
子问题一:DNS 解析失败
Android 从后台唤醒时,connectivity_plus 已经报告网络"已连接",但底层网络栈(包括 DNS 服务)尚未完全就绪。onAppResumed 立即触发 _doConnect(),DNS 查询失败,报 errno=7。
原有的 catch 块把这个错误当普通网络异常处理,走指数退避(第 N 次可能已经等几十秒),用户感知到明显延迟。
子问题二:离线队列搁浅
onAppResumed 触发重连,连接成功后调用的是 syncIncremental(),只从服务端拉取变更,不重放本端的 sync_queue。Android 后台期间的操作积压在 sync_queue 里没有上报,Win 端永远看不到。
根因
两个独立的问题:
onAppResumed没有给网络栈留出初始化时间,DNS 错误也没有单独识别处理- 重连后的同步策略没有区分"纯网络抖动"和"从后台恢复"两种场景,一律用轻量的
syncIncremental,导致离线队列数据无法上报
修复
DNS 问题:两处改动——onAppResumed 延迟 500ms 再触发重连;_doConnect 的 catch 块单独识别 DNS 错误,重置退避计数,1s 后直接重试:
dart
// onAppResumed 加延迟
Future.delayed(const Duration(milliseconds: 500), () {
if (_active && !_isShuttingDown) _doConnect();
});
// DNS 错误单独处理(多平台兼容)
bool _isDnsError(Object e) {
if (e is! SocketException) return false;
final msg = e.message.toLowerCase();
return msg.contains('failed host lookup') ||
msg.contains('no address associated with hostname') ||
(e.osError?.errorCode == 7);
}
if (_isDnsError(e)) {
_isConnecting = false; // 释放并发锁(关键!)
_retryCount = 0; // 重置退避,不惩罚性等待
Future.delayed(const Duration(seconds: 1), () {
if (_active && !_isShuttingDown) _doConnect();
});
return;
}注意 _isConnecting = false 必须在 DNS 失败分支里显式重置,否则并发锁永远不释放,之后所有重连都会被拦截。
数据不一致问题:以本地队列状态驱动同步策略选择,完全消除标志位的副作用:
dart
// 连接成功后
SyncService.instance.hasPendingQueue().then((hasQueue) {
if (hasQueue || _resumedFromBackground) {
// 队列非空 → 必须 syncAll 重放队列
// 从后台恢复 → 也用 syncAll 确保完整性
_resumedFromBackground = false;
SyncService.instance.syncAll();
} else {
// 纯网络抖动,队列为空 → 轻量增量同步即可
SyncService.instance.syncIncremental();
}
});额外加入定时兜底机制:连接成功后启动 5 分钟定时器,无论其他机制是否正常工作,最多 5 分钟内数据必然一致:
dart
_syncTimer = Timer.periodic(const Duration(minutes: 5), (_) {
if (AuthService.instance.isLoggedIn && _active) {
SyncService.instance.syncAll();
}
});最终同步体系的三层保障:
| 层级 | 触发时机 | 最大延迟 |
|---|---|---|
| 实时推送(SSE) | 有变更立即推送 | 秒级 |
| 重连追赶(smartSync) | 断线重连后 | 秒级 |
| 定时兜底(15min smartSync / 60min syncAll) | 上层机制失效时 | ≤15 分钟(60min 全量自愈) |
演进说明:Bug 6 的即时修复(后台恢复用
syncAll、5 分钟定时兜底)后来在 第十一章 被统一重构为基于服务端时间戳的smartSync三路决策 + 15min / 60min 双定时兜底。本节代码保留了当时的修复原貌,当前的同步策略以第十一章为准。
Bug 7:多端数据不一致——同步链路三层断裂
症状
Android 端在线完成一项待办,Win 端随后启动登录,等待超过 5 分钟后数据仍未同步,Win 端看不到 Android 的变更。
排查
通过日志确认时间线:
16:26:37 Android PATCH /todos/:id → 200(操作已上报服务端)
16:26:38 Android 全量同步完成,共 13 条
16:29:31 Win 启动,syncAll() 开始
16:29:32 Win SSE 连接成功,触发全量同步
16:29:32 Win GET /todos/ → 200,共 13 条(服务端返回了数据)日志显示 Win 端成功拉取了 13 条数据,但 Android 的变更没有出现。服务端数据是正确的,问题在客户端的合并逻辑。
根因:三层嵌套 Bug
深入排查后,发现同步链路上存在三处相互关联的错误:
第一层(最底层):Todo 模型缺少 updatedAt 字段
dart
// 原始模型,没有 updatedAt
class Todo {
final DateTime createdAt;
// ← 缺少 updatedAt
}整个同步比较链路依赖 updatedAt 判断"谁更新",但模型层根本没有这个字段,所有上层的比较都是错的。
第二层:syncFromServer 用 createdAt 代替 updatedAt 比较
dart
// 错误代码
final serverUpdatedAt = todo.createdAt.millisecondsSinceEpoch; // ← 用了 createdAt!
final localUpdatedAt = local.updatedAt;
if (serverUpdatedAt >= localUpdatedAt) {
await _db.updateTodo(...); // 条件几乎永远为 false
}createdAt 是创建时间,永远不变。Android 完成待办时只有 updatedAt 变化,createdAt 不变,所以 serverUpdatedAt(createdAt)< localUpdatedAt(updatedAt),服务端的更新被丢弃。
第三层:toModel() 和 toCompanion() 没有映射 updatedAt
dart
// toModel() 缺少 updatedAt 映射
model.Todo toModel() => model.Todo(
createdAt: DateTime.fromMillisecondsSinceEpoch(createdAt),
// ← 没有映射 updatedAt,Todo 对象的 updatedAt 永远等于 createdAt
);
// toCompanion() 写入时用当前时间覆盖服务端时间
TodosCompanion toCompanion() => TodosCompanion(
updatedAt: Value(DateTime.now().millisecondsSinceEpoch), // ← 丢失了服务端的 updatedAt
);即使前两层修好,第三层也会让服务端的 updatedAt 在写入本地时被当前时间覆盖,下次比较再次失效。
三层 Bug 叠加效果:服务端数据拉取成功,但合并时永远以本地旧数据为准,多端同步形同虚设。
修复
第一步:Todo 模型加 updatedAt 字段(可选参数,默认值为 createdAt):
dart
class Todo {
final DateTime createdAt;
final DateTime updatedAt;
Todo({
required this.createdAt,
DateTime? updatedAt,
}) : updatedAt = updatedAt ?? createdAt;
}第二步:_todoFromJson 解析服务端返回的 updated_at:
dart
Todo _todoFromJson(Map<String, dynamic> j) => Todo(
createdAt: DateTime.fromMillisecondsSinceEpoch(j['created_at'] as int),
updatedAt: j['updated_at'] != null
? DateTime.fromMillisecondsSinceEpoch(j['updated_at'] as int)
: DateTime.fromMillisecondsSinceEpoch(j['created_at'] as int),
);第三步:toModel() 补充 updatedAt 映射:
dart
model.Todo toModel() => model.Todo(
createdAt: DateTime.fromMillisecondsSinceEpoch(createdAt),
updatedAt: DateTime.fromMillisecondsSinceEpoch(updatedAt), // ← 补上
);第四步:拆分本地写和服务端同步两条路径,服务端同步时保留原始 updatedAt:
dart
// 服务端同步专用方法,保留服务端 updatedAt
Future<void> insertTodoFromServer(Todo todo, String userId) => ...
Future<void> updateTodoFromServer(Todo todo, String userId) => ...
// 本地写操作仍用当前时间
Future<void> insertTodo(TodosCompanion companion) => ...第五步:syncFromServer 改用 updatedAt 比较,并调用服务端专用写入方法:
dart
final serverUpdatedAt = todo.updatedAt.millisecondsSinceEpoch; // ← 改用 updatedAt
final localUpdatedAt = local.updatedAt;
if (serverUpdatedAt >= localUpdatedAt) {
await _db.updateTodoFromServer(todo, userId); // ← 保留服务端时间
}修复后数据同步链路完整:
服务端返回 updated_at
→ _todoFromJson 解析为 Todo.updatedAt
→ syncFromServer 用 updatedAt 正确比较
→ updateTodoFromServer 写入时保留服务端 updatedAt
→ toModel() 读出时正确映射 updatedAt
→ 下次同步比较依然准确教训:多端同步的正确性依赖"时间戳链路"的完整性。模型层、解析层、比较层、写入层任何一处断裂,都会导致同步静默失败——数据拉取成功,但合并时被旧数据覆盖,表面上看不出任何错误。
9.10 Nginx完整配置
nginx
# SSE 专属 location 块
location /events/ {
proxy_pass http://127.0.0.1:8080;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# SSE 关键配置:关闭连接复用,保持长连接
proxy_set_header Connection '';
# 关闭缓冲:确保数据实时透传,不积压
proxy_buffering off;
proxy_cache off;
# 超时配置
proxy_connect_timeout 10s; # 连接建立超时(短,快速失败)
proxy_read_timeout 86400s; # 读超时(24h,长连接不被切断)
proxy_send_timeout 86400s; # 写超时
# 关闭 gzip:压缩会导致数据积压,SSE 消息本身已经很小
gzip off;
}
# 在 server 块级别设置
keepalive_timeout 90s; # 大于心跳间隔(25s)的 3 倍各参数详解
proxy_buffering off + proxy_cache off
这是 SSE 能否正常工作的关键。Nginx 默认会缓冲后端响应,等缓冲区满了再统一转发给客户端。对于 SSE 来说,每条消息只有几十字节,永远填不满缓冲区,数据就会一直积压在 Nginx 内部,客户端什么也收不到。
关闭缓冲后,后端每次 response.add() 的数据都会立即透传给客户端。
proxy_set_header Connection ''
默认情况下,Nginx 会向后端发送 Connection: close Header,导致每次请求后端都关闭连接。设置为空字符串后,Nginx 使用 HTTP/1.1 的持久连接与后端通信,SSE 长连接才能维持。
proxy_http_version 1.1
必须使用 HTTP/1.1,HTTP/1.0 不支持持久连接,SSE 会立即断开。
proxy_read_timeout 86400s
设为 24 小时,确保 Nginx 不会因为"太久没有数据"而主动切断长连接。虽然后端每 25 秒会发一次心跳,正常情况下不会触发超时,但将其设为极大值是 SSE 场景的业界标准做法,提供额外的安全边际。
keepalive_timeout 90s
控制客户端到 Nginx 的 Keep-Alive 连接超时。必须大于后端心跳间隔,否则 Nginx 会在两次心跳之间把连接掐断。
取值逻辑:后端心跳 25s × 3 = 75s,设为 90s 留有容差。
proxy_connect_timeout 10s
Nginx 连接后端的超时,设为较短的值(10s),让连接失败快速暴露,不要在建立阶段挂太久。与客户端的 10s 超时形成呼应。
gzip off
SSE 消息体积小(几十字节),压缩收益几乎为零,但压缩流本身会引入缓冲行为,可能导致数据积压。关闭 gzip 是 SSE 场景的标准配置。
普通 API 路由无需特殊配置
只有 location /events/ 需要上述特殊处理,其他 API 路由(/todos/、/auth/ 等)走默认的 Nginx 配置即可,不需要关闭缓冲。
nginx
# 普通 API 路由,默认配置
location / {
proxy_pass http://127.0.0.1:8080;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
# 不需要关闭缓冲,默认配置对短请求更高效
}9.11 优化效果对比
稳定性
优化前:多端同步是"碰运气"的,应用运行几十分钟后大概率出现单向或双向静默,需要手动重启恢复。
优化后:连接在后台自动维护,Watchdog 保证最长 35 秒内检测到假死并重连,用户无需感知。长时间运行不再出现需要重启才能恢复的情况。
断线恢复时间
优化前:断线后依赖 connectivity_plus 的网络变化事件触发重连,如果网络是"半断"状态(IP 未变但实际无法通信),可能永远不会触发,只能等用户重启。
优化后:Watchdog 35 秒硬超时兜底,任何断线场景最长 35 秒内强制重连。App 从后台切回前台时立即重连,不等 Watchdog。
退出连接清理
优化前:客户端退出后后端的僵尸连接要等 1 分 40 秒(TCP TIME_WAIT)才清理,期间连接数虚高,广播会遍历僵尸连接。
优化后:
- 退出登录:
POST /auth/logout同时调用unregister(deviceId),毫秒级清理 - Win11 托盘退出:
DELETE /events/connection主动通知后端,在进程销毁前完成清理
多设备并发
优化前:同一用户的多台设备被识别为同一台(缺少 X-Device-Id),后来的连接覆盖前面的,始终只有 1 条活跃连接。
优化后:每台设备独立的 deviceId,双 Map 联动架构支持同一用户多台设备并发在线,连接数等于实际在线设备数,广播精准到达每台设备。
资源开销
优化前:N 个连接 = N 个心跳定时器,连接数越多资源消耗越大。
优化后:全局单一心跳定时器,无论多少连接都只有 1 个定时器在运行。unregister 从 O(N) 遍历降为 O(1) 直接查找。